Espressioni regolari cheat sheet

2 Febbraio 2007
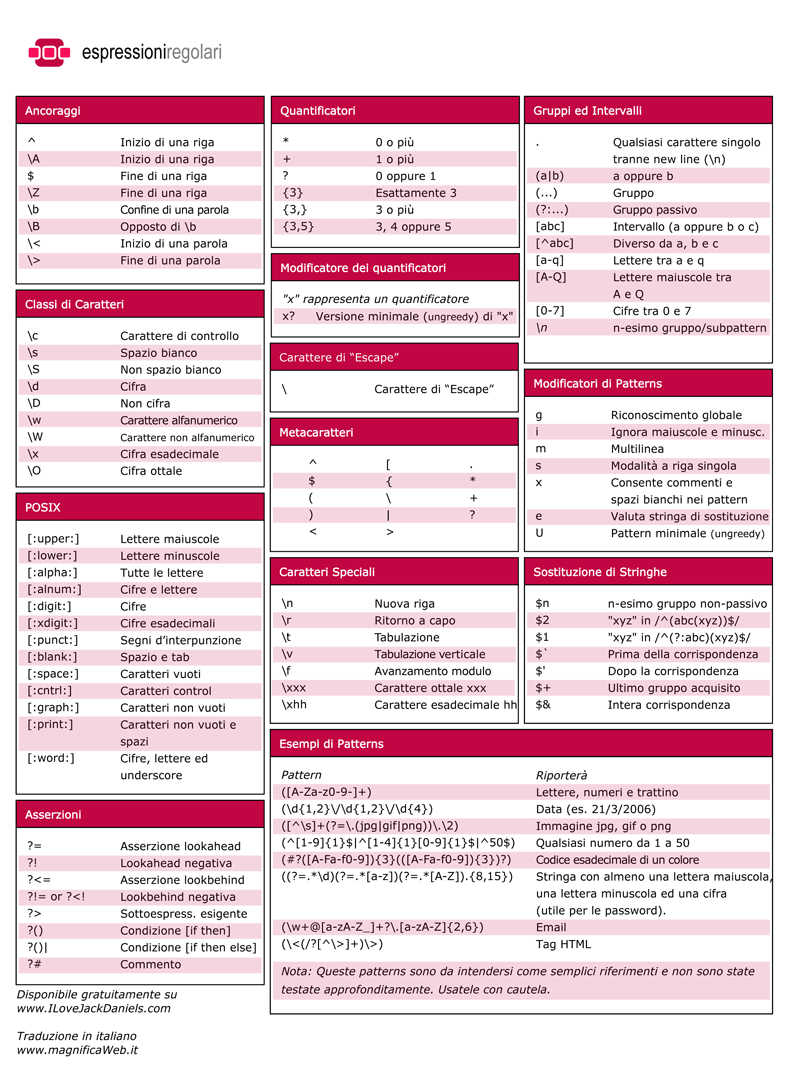
Questo cheat sheet per le espressioni regolari è la traduzione in italiano del Regular Expression Cheat Sheet di Dave Child. E’ stato disegnato per essere stampato su un foglio A4 e rimanere sulla scrivania di designer e sviluppatori: spero possa rendervi la vita un po’ più facile. In questo articolo riporto anche una breve descrizione di quello che troverete nel cheat sheet, ma se siete impazienti potete scaricare direttamente il cheat sheet in italiano.
{kind=link}
Ecco alcuni dettagli aggiuntivi per poter comprendere meglio il significato delle varie sezioni del foglio riassuntivo. Spero che questi piccoli esempi possano essere di aiuto a tutti quelli che non sono molto abituati all’utilizzo delle espressioni regolari.
Vorrei anche sottolineare che non tutto ciò che troverete in questo foglio riassuntivo funzionerà in ogni linguaggio che supporta le espressioni regolari. Infatti ogni linguaggio implementa l’espressioni regolari in maniera più o meno differente, ed in alcuni il supporto non è completo.
Ancoraggi
Gli ancoraggi indicano la posizione, all'interno del testo esaminato, che l'espressione regolare deve verificare. Per esempio, un pattern che verifica un numero all’inizio di una stringa potrebbe essere il seguente, dove “^” indica l’inizio della stringa.
^[0-9]+
Senza il simbolo “^”, il pattern verificherebbe ogni numero all’interno di una stringa.
Classi di caratteri
Nelle espressioni regolari una classe di caratteri verifica una selezione di caratteri. Per esempio, “\d” cercherà una cifra da 0 a 9. “\w” troverà corrispondenza con qualsiasi cifra e lettera (compreso l’underscore), mentre “\W” troverà corrispondenza con tutto tranne cifre e lettere (ed underscore). Un pattern per identificare una lettera, una cifra o uno spazio bianco potrebbe essere il seguente:
[\w\s]
POSIX
Lo standard POSIX è relativamente una nuova addizione alla famiglia delle espressioni regolari e come idea di base ricorda le classi di caratteri. In pratica POSIX permette di usare delle scorciatoie per identificare dei particolari gruppi di caratteri.
Asserzioni
All’inizio quasi tutti trovano delle difficoltà con le asserzioni. Ma una volta che avrete preso familiarità con le asserzioni le userete frequentemente. Praticamente permettono di dire: “Voglio trovare in questo documento ogni parola che contenga una ‘q’, ma che questa ‘q’ non sia seguita da ‘werty’”
[^\s]*q(?!werty)[^\s]*
L’esempio riportato inizia a cercare caratteri che non siano “spazio bianco” ([^\s]*), poi una “q”. A questo punto il parser raggiunge l’asserzione “lookahead” (?!werty). Questo rende la “q” condizionata da ciò che la segue. La “q” sarà verificata soltanto se l’asserzione risulta vera. In questo caso l’asserzione è negativa. E quindi risulterà vera se non troverà ciò che sta cercando.
Il parser controlla i caratteri che seguono la “q” e se questi sono diversi da “werty” la “q” è verificata. Poi prosegue trovando caratteri che non siano spazi bianchi
Quantificatori e Modificatore dei Quantificatori
I quantificatori permettono di specificare una parte di un pattern che deve essere trovato un certo numero di volte. Per esempio, l’espressione regolare abcx{1,2}d verificherà le parole abcxd e abcxxd, ma non verificherà le parole abcd e abcxxxd.
I quantificatori hanno un comportamento di default “ingordo” (greedy). Per questo il quantificatore “+”, che significa “uno o più”, cercherà di verificare il maggior numero di ripetizioni possibili. Quando non si vuole questo comportamento, si può far agire un quantificatore in maniera “minimale” (ungreedy), utilizzando un modificatore. Considerate il seguente codice :
".*"
Troverà del testo contenuto tra virgolette. Però, potreste avere una riga come la seguente:
<a href="helloworld.htm" title="Hello World">Hello World</a>
Il pattern utilizzato identificherà la seguente stringa:
"helloworld.htm" title="Hello World"
Il quantificatore “*” è stato troppo ingordo, identificando la maggior quantità possibile di testo.
Considerate questo nuovo pattern:
".*?"
Questo nuovo pattern implementa il modificatore “?” e cerca di individuare la stringa ricercata con il minor numero di caratteri possibili. Per questo motivo il contenuto tra virgolette sarà individuato in maniera separata:
"helloworld.htm""Hello World"
Carattere di Escape e Metacaratteri
Nelle espressioni regolari alcuni caratteri assumono dei significati speciali (metacatteri) per definire alcune proprietà all’interno dei pattern. Questo rappresenta un problema se volete individuare all’interno di una stringa un metacarattere con il proprio significato letterale. Ad esempio, se volete individuare un “.” all’interno di una stringa, non potete utilizzare il carattere “.” perché all’interno di una espressione regolare assumerebbe il significato di qualsiasi carattere ad eccezione del new line. Per far assumere ad un metacarattere il proprio significato letterale è necessario anteporre il carattere di escape (“\”, backslash).
Il carattere di escape che precede un metacarattere dice al parser di trattare quel metacarattere con il proprio significato letterale e non quello speciale.
Il pattern per individuare un “.” è:
\.
Caratteri Speciali
I caratteri speciali nelle espressioni regolari rappresentano degli elementi inusuali. Esempi di elementi inusuali sono new line, ritorno a capo, tabulazioni, ecc. Questi caratteri speciali usano il carattere di escape per indicare al parser che il carattere che segue deve essere trattato come un carattere speciale e non come una normale lettera o cifra.
Gruppi ed Intervalli
Gruppi ed intervalli sono veramente molto utili. Gli intervalli sono la parte più facile da cui iniziare. Permettono di specificare un insieme di caratteri da individuare. Per esempio, se volete vedere se una stringa contiene un carattere esadecimale (da zero a nove e da a ad f), potreste usare questo intervallo:
[A-Fa-f0-9]
Se invece volete vedere se la stringa non contiene quei caratteri, potrete usare un intervallo negativo. In questo caso saranno individuati tutti i caratteri tranne quelli che vanno da 0 a 9 e da a ad f:
[^A-Fa-f0-9]
I gruppi rivestono un ruolo importante nelle espressioni regolari e sono solitamente utilizzati quando si vogliono usare alcune alternative (or) all’interno di un pattern. I gruppi sono anche usati per avere un riferimento ad una parte del pattern da richiamare in seguito all’interno dello stesso pattern. I gruppi sono anche usati nelle sostituzioni di stringhe.
Per usare un’alternativa è molto semplice. Il seguente pattern indicherà “ab” oppure “cd”:
(ab|cd)
Se volete far riferimento ad un precedente gruppo, potete usare “\n”, dove “n” è il numero del gruppo. Potreste aver bisogno di individuare “aaa” o “bbb”, seguito da almeno una cifra, seguita dalle stesse tre lettere trovate inizialmente. Questo potrebbe essere fatto utilizzando i gruppi nel seguente modo:
(aaa|bbb)[0-9]+\1
Il pattern precedente individua “aaa” oppure “bbb”, ed identifica le lettere trovate come primo gruppo. In seguito è cercata almeno una cifra ([0-9]+), poi è cercato nuovamente il primo gruppo, cioè le stesse lettere trovate all’inizio del pattern. La stringa “aaa123bbb” non soddisfa il pattern, perché dopo le cifre “123” è ancora cercato “aaa”.
Modificatori di Patterns
I modificatori di patterns permettono di cambiare il modo in cui funziona il parser. Per esempio, il modificatore “i” dirà al parser di non distinguere tra lettere maiuscole o minuscole.
Nel linguaggio Perl, le espressioni regolari iniziano e finiscono con un carattere identico. Si può utilizzare un qualsiasi carattere (solitamente “/”), ed un pattern avrà il seguente aspetto:
/pattern/
I modificatori si aggiungono alla fine del pattern, dopo il delimitatore:
/pattern/i
Sostituzione di Stringhe
La sostituzione di stringhe è uno degli strumenti più utili delle espressioni regolari. Potete usare “$n” per indicare gruppi che sono stati individuati durante la valutazione delle espressione regolare.
Diciamo che desiderate rendere con un carattere grassetto tutte le istanze della parola “pippo” contenute in un blocco di testo. Dovrete usare una funzione per la sostituzione delle stringhe, che potrebbe assomigliare alla seguente:
replace(pattern, sostituto, testo-da-sostituire)
Il primo parametro è il pattern, che assomiglierà a quello riportato di seguito(notate i tre gruppi di parentesi tonde che definiscono altrettanti gruppi):
([^A-Za-z0-9])(pippo)([^A-Za-z0-9])
Questo pattern troverà tutte le istanze della parola “pippo”, purché sia preceduta e seguita da dei caratteri non-alfanumerici.
Il vostro sostituto potrebbe essere:
$1<strong>$2</strong>$3
e rimpiazzerà tutte le occorrenze di “pippo”. La sostituzione parte con il primo carattere non-alfanumerico trovato ($1), altrimenti cancelleremmo il carattere che precede “pippo”. Lo stesso avviene alla fine con il terzo gruppo. Al centro aggiungiamo il tag <strong> per rendere in grassetto tutte le ricorrenze della parola “pippo”, il nostro secondo gruppo ($2).
Merita una menzione anche l’esistenza dei gruppi “passivi”. Questi gruppi sono ignorati durante i processi di sostituzione.
Esempi di Patterns
Per finire, sono riportati alcuni esempi di patterns. Questi patterns sono riportati per mostrare come si presentano alcune espressioni regolari che si utilizzano nel lavoro di tutti i giorni, e per dare una piccolissima idea della moltitudine di usi delle espressioni regolari. Vorrei comunque sottolineare come i patterns riportati non siano stati verificati approfonditamente e siano da considerare come semplici esempi da cui prendere spunto.
Ora non vi resta altro da fare che scaricare il cheat sheet delle espressioni regolari:
Ti è piaciuto questo articolo? Aggiungilo a: del.icio.us